애그리게이트와 일관성 경계
불변조건, 동시성, 락
- 불변조건은 항상 참이어야하는 조건이다. 비지니스 규칙이다.
- 예를 들면
호텔 예약 시스템에서 중복 예약을 허용하지 않는다.는 불변 조건이다.
주문 라인 수량보다 더 작은 배치에 라인을 할당할 수는 없다.라는 불변 조건이 있다고 가정하자.- 두 사용자가 동시에 재고 수량인 5인 배치에 5개 주문 라인을 배치하려한다.
- 동시에 요청이 오면 재고 수량이 5임에도 5개 주문 라인 2개가 배치될 수 있다.
- 동시성 문제다.
- 락이 필요하며 이는 교착상태, 그리고 성능에 이슈가 된다.
애그리게이트란?
- 불변조건과 동시성 이슈를 해결하고 싶다.
- 안전하게 데이터베이스 전체를 락을 걸 수 있지만 그럴 필요 없다.
DEADLY-SPOON, FLIMSY-DESK 개별 상품을 동시에 쓰여질 수 있다.- 한 상품이 동시에 쓰여지는 것을 막아야한다.
- 애그리게이트는 락 단위를 지키며 일관된 도메인 모델 변경을 위한 단일 진입점이다.
- 애그리게이트로만 도메인 모델 변경이 가능하니 시스템에 대한 추론도 쉬워지는 장점이 있다.
애그리게이트 선택
- 변경 단위는 한 상품이다.
- 배치 컬렉션을 가지는
Product라는 애그리거트를 만든다.
class Product:
def __init__(self, sku: str, batches: List[Batch]):
self.sku = sku
self.batches = batches
def allocate(self, line: OrderLine) -> str:
try:
batch = next(b for b in sorted(self.batches) if b.can_allocate(line))
batch.allocate(line)
return batch.reference
except StopIteration:
raise OutOfStock(f"Out of stock for sku {line.sku}")
한 애그리게이트 = 한 저장소
- 애그리게이트로 변경하니 애그리게이트 저장소 또한 필요하다.
Batch 는 변경 진입로가 아니니 기존 BatchRepository를 ProductRepository로 변경한다.
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
self.session = session
def add(self, product):
self.session.add(product)
def get(self, sku):
return self.session.query(model.Product).filter_by(sku=sku).first()
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork,
):
with uow:
product = uow.products.get(sku=sku)
if product is None:
product = model.Product(sku, batches=[])
uow.products.add(product)
product.batches.append(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = product.allocate(line)
uow.commit()
return batchref
성능은 어떨까?
- 저장소로부터 한
Product에 모든 Batch를 가져와 부담으로 느껴질 수 있다.
- 모든
Batch를 가져올 때 한번의 쿼리로 가져오고 적은 숫자 Batch만 가진다고 가정한다.
- 만약
Batch가 정말 많은 경우 지연 읽기로 문제를 해결 할 수 있다.
- 위 방법 모두 무리라면 애그리게이트 설계를 다시 고민해볼 필요있다.
버전 번호와 낙관적 동시성
batches 테이블에 락을 걸지 않고 한 상품 동시쓰기를 어찌 막을까?version_number를 이용할 수 있다.- 버전 정보로 올바른 요청인지 확인 후 데이터베이스에 반영한다.
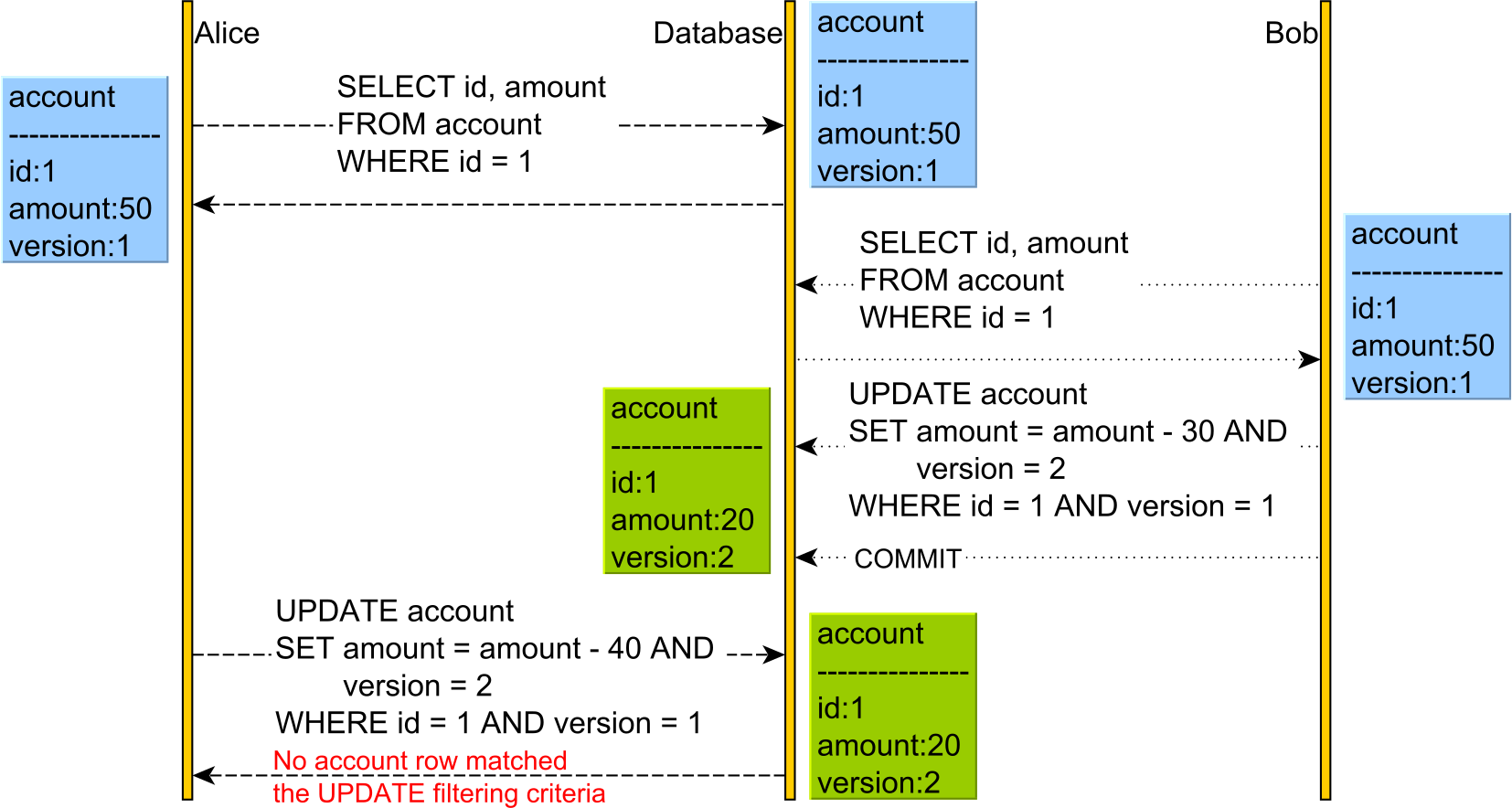
- 동시쓰기 이슈가 잘 없을 것으로 생각, 일단 요청을 받아주고 조건에 맞지 않으면 실패한다.
- 구현 방법은 여러가지가 있다.
- 서비스 계층에서
version_number 관리 + isolation level을 REPEATABLE READ로 지정
- 저장소에서
version_number 관리
- 1번으로 구현해본다.
class Product:
def __init__(self, sku: str, batches: List[Batch], version_number: int = 0):
self.sku = sku
self.batches = batches
self.version_number = version_number
def allocate(self, line: OrderLine) -> str:
try:
batch = next(b for b in sorted(self.batches) if b.can_allocate(line))
batch.allocate(line)
self.version_number += 1
return batch.reference
except StopIteration:
raise OutOfStock(f"Out of stock for sku {line.sku}")
DEFAULT_SESSION_FACTORY = sessionmaker(bind=create_engine(
config.get_postgres_uri(),
isolation_level="REPEATABLE READ",
))
- Postgresql에서
REPEATABLE READ는 특정 row를 읽고 다시 저장할 때 처음 가져올 때 값이랑 다르면 실패를 낸다.
데이터 무결성 규칙 테스트
def try_to_allocate(orderid, sku, exceptions):
line = model.OrderLine(orderid, sku, 10)
try:
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
product = uow.products.get(sku=sku)
product.allocate(line)
time.sleep(0.2)
uow.commit()
except Exception as e:
print(traceback.format_exc())
exceptions.append(e)
def test_concurrent_updates_to_version_are_not_allowed(postgres_session_factory):
sku, batch = random_sku(), random_batchref()
session = postgres_session_factory()
insert_batch(session, batch, sku, 100, eta=None, product_version=1)
session.commit()
order1, order2 = random_orderid(1), random_orderid(2)
exceptions = []
try_to_allocate_order1 = lambda: try_to_allocate(order1, sku, exceptions)
try_to_allocate_order2 = lambda: try_to_allocate(order2, sku, exceptions)
thread1 = threading.Thread(target=try_to_allocate_order1)
thread2 = threading.Thread(target=try_to_allocate_order2)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
[[version]] = session.execute(
"SELECT version_number FROM products WHERE sku=:sku",
dict(sku=sku),
)
assert version == 2
[exception] = exceptions
assert "could not serialize access due to concurrent update" in str(exception)
orders = session.execute(
"SELECT orderid FROM allocations"
" JOIN batches ON allocations.batch_id = batches.id"
" JOIN order_lines ON allocations.orderline_id = order_lines.id"
" WHERE order_lines.sku=:sku",
dict(sku=sku),
)
assert orders.rowcount == 1
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
uow.session.execute("select 1")
비관적 동시성 제어
- 애초에 충돌이 많이 날 것으로 고려, 동시에 같은 행 읽기를 방지할 수 있다.
- 한 트랙잭션이 읽고 update 할 때까지 다른 트랙잭션은 기다려야한다.
SELECT FOR UPDATE를 사용하면 된다.
def get(self, sku):
return self.session.query(model.Product) \
.filter_by(sku=sku) \
.with_for_update() \
.first()
낙관적 동시성 제어 vs 비관적 동시성 제어
- 낙관적 동시성 제어는 충돌이 많이 없을 것으로 생각, 충돌이 나면 실패낸다. 락이 없어서 빠르다.
- 비관적 동시성 제어는 충돌이 많이 있을 것으로 생각, 충돌이 나지 않도록 미리 락이 걸려있는 경우 대기한다.
- 충돌이 많은 경우 바로 실패내기보다 락으로 충돌을 방지하고 실패를 덜내는 것이 사용성에 더 좋을 수도 있다.
- https://stackoverflow.com/a/41029731/2578380
정리
- 애그리게이트는 도메인 모델에 대한 진입점이다.
- 애그리게이트는 일관성 경계에 대한 책임을 진다.
- 애그리게이트와 동시성 문제는 공존한다.
- 동시성 제어에는 낙관적/비관적 제어 방법이 있다.